
Picture: PetaPixel
Teknologi.id - Bagaimana jika kecerdasan buatan dapat menafsirkan imajinasi Anda, mengubah gambar dari pikiran Anda langsung menjadi kenyataan? Meskipun terdengar seperti plot novel cyberpunk, para peneliti menemukan bahwa mereka dapat merekonstruksi gambar beresolusi tinggi berdasarkan data fMRI dari aktivitas otak manusia, dan merekonstruksi pengalaman visual, dengan mengandalkan model difusi laten (LDM) AI yang disebut pencitraan Stable Diffusion.
Computer vision selalu terinspirasi oleh ilmu saraf dan salah satu tujuannya memungkinkan sistem buatan untuk melihat dunia seperti yang dilihat seseorang. Antara lain, kemajuan ilmu saraf dan kecerdasan buatan telah menunjukkan bahwa ada perbandingan langsung antara representasi laten yang ada di otak manusia dan arsitektur jaringan saraf.
Tim yang dipimpin oleh peneliti Yu Takagi dan Shinji Nishimoto menulis dalam sebuah makalah yang diterbitkan pada bulan Desember kemarin bahwa, tidak seperti penelitian-penelitian lain sebelumnya, mereka tidak perlu melatih atau menyempurnakan model kecerdasan buatan untuk membuat gambarnya.
Baca juga: Gratis! Begini Cara Bikin CV ATS Pakai AI di Situs ResumAI
Beberapa studi sebelumnya telah mencoba rekonstruksi citra beresolusi tinggi, tetapi hanya setelah pelatihan dan penyempurnaan model generatif. Hal ini menyebabkan adanya limitasi karena melatih model kompleks adalah tugas yang sulit, dan neurobiologi tidak memiliki banyak sampel untuk dikerjakan. Hingga saat ini, belum ada peneliti lain yang mencoba menggunakan model difusi untuk rekonstruksi visual.
Studi yang baru ini menunjukkan sekilas potensi proses internal model difusi, para peneliti menyimpulkan, bahwa mereka memberikan interpretasi kuantitatif model dari sudut pandang biologis untuk pertama kalinya.
Tim yang bekerja di Graduate School of Frontier Biosciences, Universitas Osaka ini menjelaskan pertama-tama mereka memprediksi representasi laten, yang merupakan model data gambar dari sinyal fMRI. Model tersebut kemudian diproses dan noise ditambahkan ke dalamnya menggunakan proses difusi. Akhirnya, para peneliti menguraikan gambar teks dari sinyal fMRI di korteks visual otak dan menggunakannya sebagai masukan untuk membuat gambar akhir yang dibuat.


Picture: PetaPixel
Pada gambar di atas, gambar di kotak merah atas menunjukkan gambar asli yang disajikan kepada individu dalam penelitian. Sedangkan gambar pada baris paling bawah merupakan citra yang direkonstruksi dari aktivitas otak manusia menggunakan Stable Diffusion, Semantic Decoder, dan fMRI image generation.
Para ilmuwan memberi individu satu set gambar dan mengambil pemindaian fMRI (functional magnetic resonance imaging) otak mereka selagi mereka berkonsentrasi pada gambar.
Mereka menggunakan Natural Scenes Dataset (NSD): “data diperoleh dari pemindai 7-Tesla fMRI selama 30-40 sesi di mana setiap subjek melihat tiga pengulangan dari 10.000 gambar.” Penulis kemudian mengambil gambar di MS COCO dan anotasi tekstual. Stable Diffusion bekerja dengan mengambil prompt tekstual, yang diubah menjadi fitur oleh model bahasa dan ini kemudian mendorong U-Net dalam membuat representasi gambar, yang kemudian diterjemahkan oleh dekoder menjadi gambar (dalam piksel).
Baca juga: Guru Jangan Mau Dicurangi Siswa! Berikut Cara Cek Plagiarisme AI Gratis
Tim menggunakan kombinasi output gambar fMRI dan Semantic Decoder untuk membuat gambar yang dihasilkan. Namun, mereka menemukan bahwa penambahan Stable Difusion ke dalam proses memungkinkan gambar akhir yang dihasilkan terlihat lebih mirip dengan gambar asli yang ditunjukkan kepada peserta.
Pelatihan atau penyempurnaan model generatif dalam yang rumit tidak diperlukan, karena kerangka kerja sederhana ini merekonstruksi gambar beresolusi tinggi dari sinyal Pencitraan Resonansi Magnetik (fMRI) fungsional menggunakan Stable Diffusion. Proses konversi teks ke gambar yang diterapkan oleh Stable Diffusion menggabungkan informasi semantik yang diekspresikan oleh teks bersyarat, sekaligus mempertahankan tampilan gambar aslinya.
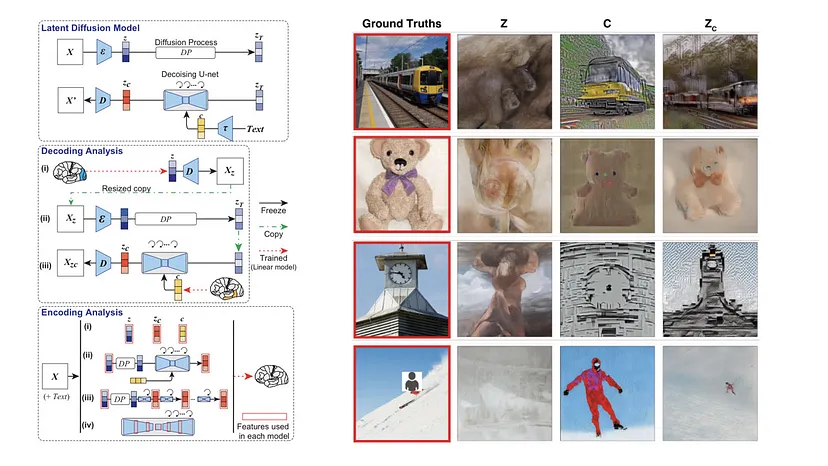
Picture: MLearning.ai
KIRI: Encoder dan decoder gambar digunakan, bersama dengan encoder teks yang disebut CLIP. Studi ini menggunakan analisis decoding untuk memecahkan kode representasi laten gambar dan teks terkait dari sinyal fMRI di berbagai bagian korteks visual, dan kemudian menggunakan representasi ini untuk merekonstruksi gambar. Studi ini juga menggunakan model pengkodean untuk memprediksi sinyal fMRI dari berbagai komponen LDM. KANAN: Gambar yang direkonstruksi untuk satu subjek yang disajikan (dalam kotak merah).
Dengan perkembangan AI generatif, semakin banyak peneliti yang menguji bagaimana model AI dapat bekerja dengan otak manusia. Pada Januari 2022, peneliti dari Radboud University di Belanda melatih jaringan AI generatif, pendahulu Stable Diffusion, untuk bekerja dengan data fMRI dari 1.050 individu unik dan mengubah hasil pencitraan otak menjadi gambar nyata.
Studi tersebut menunjukkan bahwa AI mampu melakukan rekonstruksi stimulus yang belum pernah terjadi sebelumnya. Dalam studi terbaru yang diterbitkan pada Desember 2022, para ilmuwan dari Universitas Osaka menemukan bahwa model difusi modern sekarang dapat memberikan rekonstruksi visual beresolusi tinggi.
(da)

Tinggalkan Komentar