
Foto: Nvidia
Teknologi.id – Raksasa teknologi cip, Nvidia, baru saja memperkenalkan sebuah teknik revolusioner yang diklaim mampu mengubah peta jalan komputasi kecerdasan buatan (AI). Teknologi baru yang dinamakan Dynamic Memory Sparsification (DMS) ini dilaporkan mampu memangkas kebutuhan memori GPU hingga delapan kali lipat. Hebatnya, penghematan besar-besaran ini diklaim tidak akan menurunkan tingkat akurasi model AI yang dijalankan.
Inovasi ini muncul di tengah krisis ketersediaan unit pemroses grafis (GPU) dan tingginya biaya operasional pusat data AI di seluruh dunia. Dengan DMS, Nvidia berupaya memecahkan kendala utama dalam pengembangan Large Language Model (LLM) modern, yaitu keterbatasan memori saat melakukan proses penalaran atau reasoning.
Solusi untuk Kendala 'Bottleneck' Memori
Dalam pengoperasian model bahasa besar, proses menghasilkan teks atau token demi token menciptakan apa yang disebut sebagai key-value cache (KV cache). KV cache adalah memori sementara yang terus membengkak seiring dengan panjangnya konteks pembicaraan atau proses berpikir model AI.
Semakin panjang proses penalaran yang dilakukan oleh chatbot, semakin besar pula ruang memori GPU yang tersedot. Kondisi ini sering kali menjadi bottleneck atau hambatan utama yang menyebabkan lonjakan biaya komputasi serta membatasi jumlah pengguna yang dapat dilayani oleh satu sistem secara bersamaan. DMS dirancang khusus untuk mengelola KV cache ini agar tetap efisien tanpa kehilangan informasi penting.
Baca juga: Stop Coding! CEO Nvidia Jensen Huang Sebut AI Bikin Programmer Tak Perlu Kode Lagi
Cara Kerja Dynamic Memory Sparsification (DMS)
Berbeda dengan metode tradisional yang menggunakan aturan tetap (heuristik) untuk menghapus data memori lama guna menghemat ruang, DMS bekerja dengan cara yang jauh lebih cerdas. Metode lama sering kali menyebabkan penurunan akurasi karena informasi penting bisa ikut terhapus secara tidak sengaja.
Sebaliknya, DMS memungkinkan model AI untuk "mengelola memorinya sendiri". Teknologi ini melatih model untuk mengenali token mana yang benar-benar relevan bagi proses penalaran berikutnya dan mana yang dapat dihapus. Nvidia juga menerapkan mekanisme delayed eviction, yakni menunda penghapusan token agar model sempat menyerap konteks penting sebelum memori dibersihkan. Dengan teknik ini, beban pada GPU dapat ditekan secara signifikan tanpa mengganggu kualitas output atau hasil jawaban dari AI.
Akurasi Tetap Terjaga, Performa Meningkat
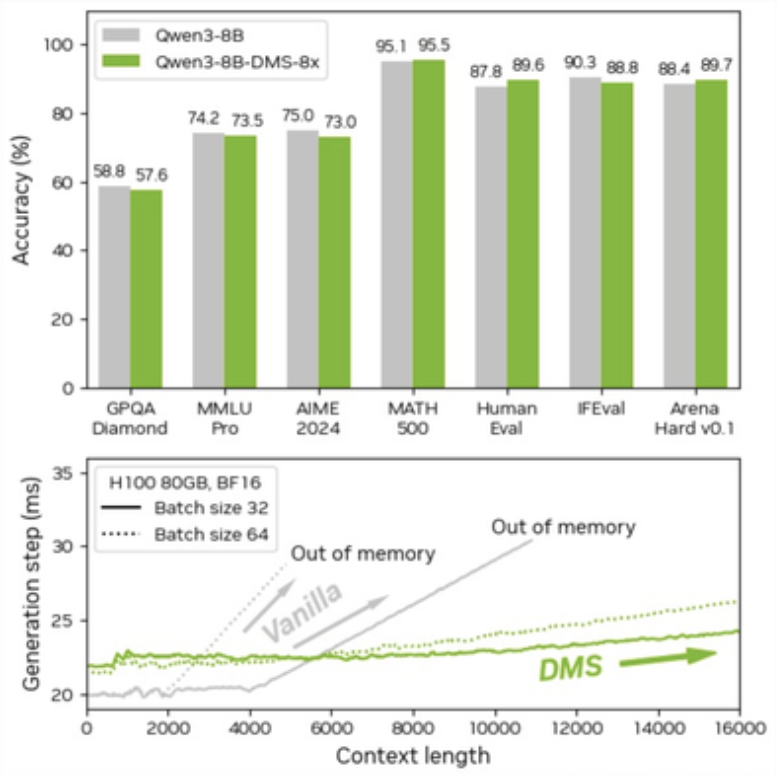
Foto: Nvidia
Dalam pengujian yang dilakukan pada sejumlah model populer seperti Qwen dan Llama, DMS menunjukkan hasil yang sangat impresif. Pada model Qwen3-8B, misalnya, tingkat akurasi tetap identik di berbagai benchmark penalaran seperti MATH 500, HumanEval, hingga AIME 2024. Bahkan, dalam beberapa skenario pengkodean (coding) dan matematika, model dengan DMS mencatat skor yang sedikit lebih tinggi dibanding versi standar.
Efisiensi memori ini berdampak langsung pada kecepatan sistem. Karena GPU tidak perlu terus-menerus membaca dan menulis data dalam jumlah besar ke memori, latensi atau keterlambatan proses menjadi berkurang, sementara throughput (jumlah data yang diproses per detik) meningkat. Model AI kini dapat memproses konteks yang jauh lebih panjang tanpa risiko kehabisan memori (out of memory).
Kompatibilitas dan Kemudahan Adopsi
Satu poin krusial dari teknologi DMS ini adalah kemudahannya untuk diadopsi oleh para pengembang. Nvidia menyatakan bahwa DMS dapat diterapkan pada model AI yang sudah dilatih sebelumnya (pretrained models) tanpa perlu melakukan pelatihan ulang dari nol yang memakan biaya mahal.
Proses adaptasinya disebut relatif ringan dan sepenuhnya kompatibel dengan infrastruktur standar yang ada saat ini. Teknologi ini telah dirilis sebagai bagian dari kerangka kerja (framework) Model Optimizer Nvidia dan dapat diintegrasikan dalam ekosistem AI populer seperti Hugging Face serta sistem yang mendukung FlashAttention. Hal ini memungkinkan perusahaan pengembang AI untuk segera mengimplementasikan teknologi ini guna menekan biaya infrastruktur mereka.
Baca juga: Nvidia Rilis Alpamayo AI, Bikin Mobil Otonom Punya Penalaran Layaknya Manusia!
Dampak Ekonomi bagi Industri AI
Bagi industri, penghematan memori hingga delapan kali lipat berarti penghematan biaya yang sangat besar. Saat ini, biaya operasional layanan AI sangat bergantung pada kapasitas memori GPU. Dengan DMS, satu buah GPU dapat menangani beban kerja yang sebelumnya membutuhkan kapasitas memori jauh lebih besar, atau melayani lebih banyak pengguna dalam satu waktu dengan perangkat keras yang sama.
Inovasi ini juga memberikan napas lega bagi perusahaan-perusahaan yang kesulitan mendapatkan suplai chip AI terbaru. Dengan mengoptimalkan perangkat yang sudah ada lewat teknologi perangkat lunak seperti DMS, Nvidia memastikan bahwa kemajuan AI tidak akan terhambat oleh keterbatasan fisik memori semata.
Baca berita dan artikel lainnya di Google News
(WN/ZA)

Tinggalkan Komentar