


Teknologi.id - Dua model baru, DeepSeek V3.2 dan DeepSeek V3.2 Special, baru-baru ini dirilis oleh startup berbasis di Hangzhou, China. Kedua model ini diklaim memiliki kemampuan yang setara dengan GPT-5 milik OpenAI dan Gemini 3.0 Pro milik Google. Klaim tersebut bukan sekadar retorika, melainkan bagian dari strategi besar China untuk menegaskan posisinya dalam perlombaan global teknologi kecerdasan buatan.
Langkah ini menandai ambisi besar China untuk menyaingi dominasi Amerika Serikat dalam industri AI. Selama bertahun-tahun, perusahaan teknologi asal AS seperti OpenAI, Google, dan Anthropic mendominasi panggung global dengan model bahasa besar (LLM) yang dianggap paling canggih. Kini, dengan hadirnya DeepSeek V3.2, peta persaingan mulai bergeser.
Sejak didirikan pada Juli 2023, DeepSeek berkonsentrasi pada pengembangan model bahasa besar (LLM) dan teknologi multimodal. Tujuannya adalah membuat model AI yang mampu memahami teks dan mengintegrasikan berbagai jenis data seperti kode, gambar, dan logika kompleks. Metode ini akan membantu DeepSeek mengatasi dua kelemahan model open-source: efisiensi komputasi dan kemampuan penalaran tingkat tinggi.
Selain itu, peluncuran DeepSeek V3.2 mencerminkan rencana jangka panjang China untuk meningkatkan ekosistem teknologi domestik. Dengan mengembangkan model yang mampu bersaing dengan GPT-5 dan Gemini 3.0 Pro, DeepSeek menargetkan pasar lokal dan berharap dapat mencapai pasar internasional. Hal ini sejalan dengan tren geopolitik di mana AS dan China bersaing di bidang teknologi AI.
Selain itu, DeepSeek menegaskan bahwa inovasi mereka tidak hanya meniru, tetapi juga menyelesaikan masalah yang membatasi model open-source. Misalnya, pemrosesan teks panjang yang tidak efektif, kemampuan agen otonom yang buruk, dan kurangnya investasi post-training. Perusahaan ini berusaha mengatasi masalah ini dan menyediakan model yang lebih efisien tanpa mengorbankan kualitas dengan memperkenalkan teknologi DeepSeek Sparse Attention (DSA).
Baca Juga: Revolusi AI dan Kuantum China, Mulai dari DeepSeek, Manus, Zhuchongzi-3
Inovasi DeepSeek Sparse Attention (DSA)
Salah satu terobosan utama DeepSeek V3.2 adalah penerapan DeepSeek Sparse Attention (DSA). Teknologi ini memungkinkan model memeriksa ulang setiap token sebelumnya dengan sistem indeks, sehingga dapat mengidentifikasi bagian penting dari riwayat teks.
Hasilnya, biaya komputasi dapat ditekan tanpa mengorbankan kualitas output. Menurut DeepSeek, DSA mampu mempercepat pemrosesan input panjang secara signifikan, meski perusahaan tidak merinci persentase peningkatannya.
Selain itu, DeepSeek meningkatkan anggaran post-training hingga 10% lebih tinggi dibandingkan pelatihan, sebuah lonjakan besar dibanding peningkatan satu persen dalam 2 tahun. Strategi ini menunjukkan fokus perusahaan pada penguatan kemampuan reasoning dan agen otonom.
DeepSeek Melangkah Maju
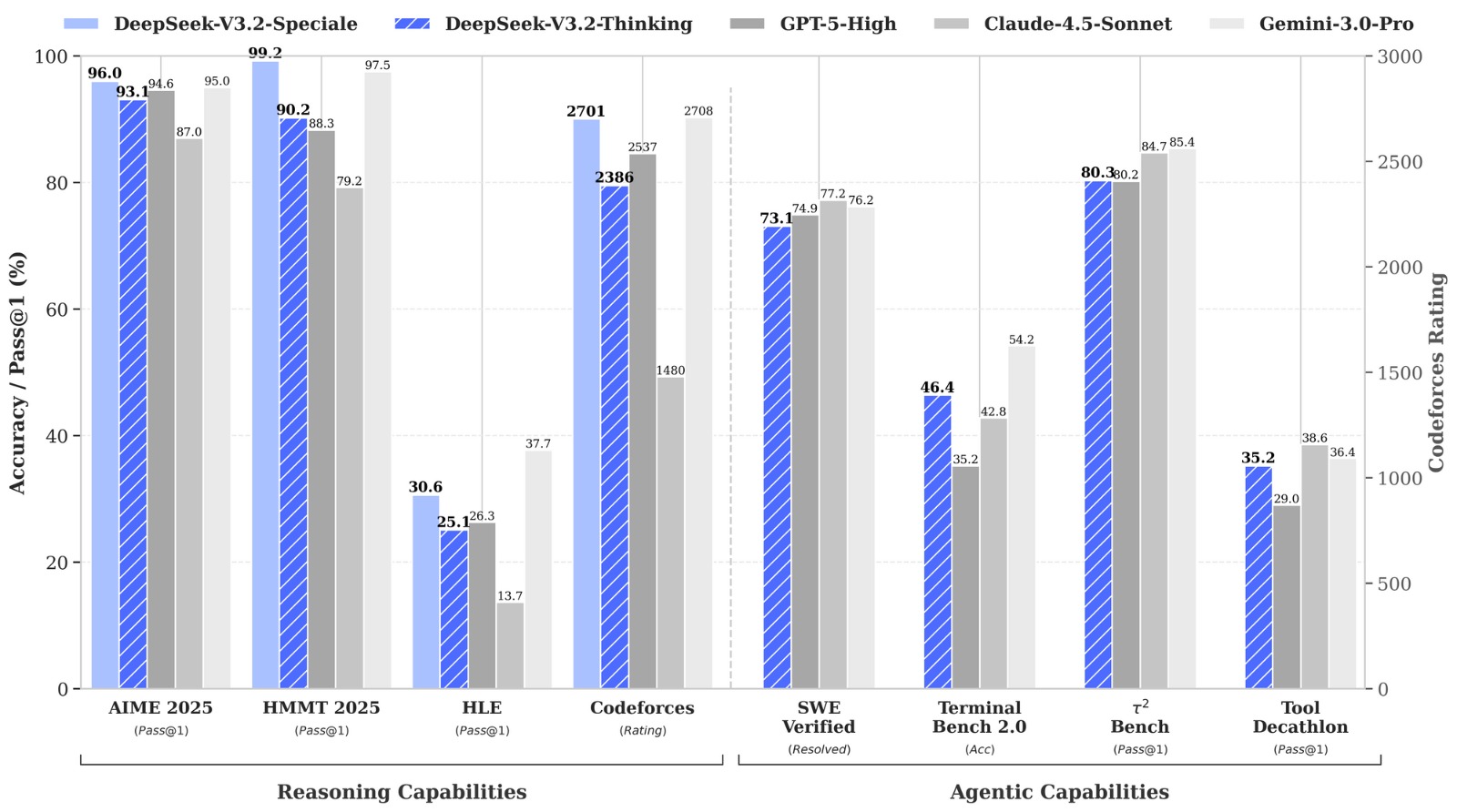
DeepSeek V3.2 diuji dalam berbagai benchmark internasional, seperti:
- AIME 2025 (kompetisi matematika) - V3.2 meraih skor 93,1% , tepat di belakang GPT-5 dengan skor 94,6%
- LiveCodeBench (pemrograman) - V3.2 mencatat 83,3% dengan diikuti GPT-5 84,5%, sementara Gemini 3 Pro Unggul dengan 90,7%
- SWE Multilingual (pengembangan software di GitHub) - V3.2 menyelesaikan 70,2% masalah, sedangkan GPT-5 dengan angka 55,3%
- Terminal Bench 2.0 - V3.2 mencatat 46,4% lebih tinggi dari GPT-5 dengan angka 35,2%, meski masih di bawah Gemini 3 Pro dengan angka 54,2%
Data ini menunjukkan bahwa DeepSeekV3.2 mampu menyaingi akan melampaui GPT-5 dalam beberapa aspek, meski Gemini 3 Pro tapi tetap unggul di sejumlah kategori.
Prestasi DeepSeek lampaui Gemini
Versi DeepSeek V3.2 Speciale dirancang dengan Komputasi Tinggi. Model ini berhasil meraih:
- Medali emas olimpiade matematika internasional 2025
- Menerima olimpiade informatika internasional 2025
- Tingkat kedua di ICPC World Final 2025
Keunggulan Speciale terletak pada penggunaan token yang jauh lebih banyak. Dalam uji CodeForce, Speciale memproses rata-rata 77.000 token, jauh di atas Gemini yang hanya mampu memproses 22.000 token.
Dengan performa ini, Speciale bahkan mampu melampaui Gemini 3 Pro dalam beberapa kategori, menjadikannya salah satu model AI paling kompetitif di dunia saat ini.
Baca Juga: Google Rilis Gemini 3 Model AI Terpintar Saingi GPT-5
Apa DeepSeek Masih Memiliki Kekurangan?
Meskipun impresif, DeepSeek mengakui bahwa V3.2 masih tertinggal dalam hal:
- Keluasan pengetahuan dibanding GPT-5 dan Gemini
- Efisien token, terutama dalam konteks panjang
- Kinerja pada tugas kompleks yang membutuhkan reasoning multi lapis
DeepSeek berencana mengatasi kelemahan ini dengan pelatihan awal yang intensif dan pengembangan synthetic environment.
Saat ini mereka telah membangun lebih dari 1800 ruang simulasi virtual serta ribuan skenario berbasis masalah nyata di GitHub untuk melatih Agen Otonom.
Persaingan Dua Raksasa China VS Amerika
Peluncuran DeepSeek V3.2 menegaskan bahwa perlombaan AI global semakin memanas. Setelah OpenAI merilis GPT-5 pada Agustus dan Google memperkenalkan Gemini 3.0 Pro pada November, DeepSeek muncul sebagai penantang serius dari China.
Menariknya, DeepSeek merilis model ini dengan lisensi Apache 2.0 di Hugging Face, sehingga dapat diakses secara gratis oleh komunitas global. Langkah ini berpotensi mempercepat adopsi dan memperluas pengaruh DeekSeek di luar China.
Baca Berita dan Artikel lainnya di Google News
(dim/sa)

